Pacman, now with ghosts.
Minimax, Expectimax,
Evaluation
TABLE OF CONTENTS
TABLE OF CONTENTS
Introduction
Welcome to Multi-Agent Pacman
Q1 (4 pts): Reflex Agent
Q2 (5 pts): Minimax
Hints and Observations
Q3 (5 pts): Alpha-Beta Pruning
Q4 (5 pts): Expectimax
Q5 (6 pts): Evaluation Function
Introduction
In this project, you will design agents for the classic version of Pacman, including ghosts. Along the way, you will implement both minimax and expectimax search and try your hand at evaluation function design.
The code base has not changed much from the previous project, but please start with a fresh installation, rather than intermingling files from project 1.
As in project 1, this project includes an autograder for you to grade your answers on your machine. This can be run on all questions with the command:
1
python autograder.py
It can be run for one particular question, such as q2, by:
1
python autograder.py -q q2
It can be run for one particular test by commands of the form:
By default, the autograder displays graphics with the -t option, but doesn’t with the -q option. You can force graphics by using the --graphics flag, or force no graphics by using the --no-graphics flag.
See the autograder tutorial in Project 0 for more information about using the autograder.
The code for this project contains the following files, available as a zip archive.
Files you’ll edit:
multiAgents.py
Where all of your multi-agent search agents will reside.
Files you might want to look at:
pacman.py
The main file that runs Pacman games. This file also describes a Pacman GameState type, which you will use extensively in this project.
game.py
The logic behind how the Pacman world works. This file describes several supporting types like AgentState, Agent, Direction, and Grid.
util.py
Useful data structures for implementing search algorithms. You don’t need to use these for this project, but may find other functions defined here to be useful.
Supporting files you can ignore:
graphicsDisplay.py
Graphics for Pacman
graphicsUtils.py
Support for Pacman graphics
textDisplay.py
ASCII graphics for Pacman
ghostAgents.py
Agents to control ghosts
keyboardAgents.py
Keyboard interfaces to control Pacman
layout.py
Code for reading layout files and storing their contents
autograder.py
Project autograder
testParser.py
Parses autograder test and solution files
testClasses.py
General autograding test classes
test_cases/
Directory containing the test cases for each question
multiagentTestClasses.py
Project 2 specific autograding test classes
Files to Edit and Submit: You will fill in portions of multiAgents.py during the assignment. Once you have completed the assignment, you will submit a token generated by submission_autograder.py. Please do not change the other files in this distribution or submit any of our original files other than this file.
Evaluation: Your code will be autograded for technical correctness. Please do not change the names of any provided functions or classes within the code, or you will wreak havoc on the autograder. However, the correctness of your implementation – not the autograder’s judgements – will be the final judge of your score. If necessary, we will review and grade assignments individually to ensure that you receive due credit for your work.
Academic Dishonesty: We will be checking your code against other submissions in the class for logical redundancy. If you copy someone else’s code and submit it with minor changes, we will know. These cheat detectors are quite hard to fool, so please don’t try. We trust you all to submit your own work only; please don’t let us down. If you do, we will pursue the strongest consequences available to us.
Getting Help: You are not alone! If you find yourself stuck on something, contact the course staff for help. Office hours, section, and the discussion forum are there for your support; please use them. If you can’t make our office hours, let us know and we will schedule more. We want these projects to be rewarding and instructional, not frustrating and demoralizing. But, we don’t know when or how to help unless you ask.
Discussion: Please be careful not to post spoilers.
Welcome to Multi-Agent Pacman
First, play a game of classic Pacman by running the following command:
1
python pacman.py
and using the arrow keys to move. Now, run the provided ReflexAgent in multiAgents.py
1
python pacman.py -p ReflexAgent
Note that it plays quite poorly even on simple layouts:
1
python pacman.py -p ReflexAgent -l testClassic
Inspect its code (in multiAgents.py) and make sure you understand what it’s doing.
Q1 (4 pts): Reflex Agent
Improve the ReflexAgent in multiAgents.py to play respectably. The provided reflex agent code provides some helpful examples of methods that query the GameState for information. A capable reflex agent will have to consider both food locations and ghost locations to perform well. Your agent should easily and reliably clear the testClassic layout:
1
python pacman.py -p ReflexAgent -l testClassic
Try out your reflex agent on the default mediumClassic layout with one ghost or two (and animation off to speed up the display):
How does your agent fare? It will likely often die with 2 ghosts on the default board, unless your evaluation function is quite good.
Note: Remember that newFood has the function asList()
Note: As features, try the reciprocal of important values (such as distance to food) rather than just the values themselves.
Note: The evaluation function you’re writing is evaluating state-action pairs; in later parts of the project, you’ll be evaluating states.
Note: You may find it useful to view the internal contents of various objects for debugging. You can do this by printing the objects’ string representations. For example, you can print newGhostStates with print(newGhostStates).
Options: Default ghosts are random; you can also play for fun with slightly smarter directional ghosts using -g DirectionalGhost. If the randomness is preventing you from telling whether your agent is improving, you can use -f to run with a fixed random seed (same random choices every game). You can also play multiple games in a row with -n. Turn off graphics with -q to run lots of games quickly.
Grading: We will run your agent on the openClassic layout 10 times. You will receive 0 points if your agent times out, or never wins. You will receive 1 point if your agent wins at least 5 times, or 2 points if your agent wins all 10 games. You will receive an additional 1 point if your agent’s average score is greater than 500, or 2 points if it is greater than 1000. You can try your agent out under these conditions with
1
python autograder.py -q q1
To run it without graphics, use:
1
python autograder.py -q q1 --no-graphics
Don’t spend too much time on this question, though, as the meat of the project lies ahead.
classReflexAgent(Agent): """ A reflex agent chooses an action at each choice point by examining its alternatives via a state evaluation function. The code below is provided as a guide. You are welcome to change it in any way you see fit, so long as you don't touch our method headers. """
defgetAction(self, gameState: GameState): """ You do not need to change this method, but you're welcome to. getAction chooses among the best options according to the evaluation function. Just like in the previous project, getAction takes a GameState and returns some Directions.X for some X in the set {NORTH, SOUTH, WEST, EAST, STOP} """ # Collect legal moves and successor states legalMoves = gameState.getLegalActions()
# Choose one of the best actions scores = [self.evaluationFunction(gameState, action) for action in legalMoves] bestScore = max(scores) bestIndices = [index for index inrange(len(scores)) if scores[index] == bestScore] chosenIndex = random.choice(bestIndices) # Pick randomly among the best
"Add more of your code here if you want to"
return legalMoves[chosenIndex]
defevaluationFunction(self, currentGameState: GameState, action): """ Design a better evaluation function here. The evaluation function takes in the current and proposed successor GameStates (pacman.py) and returns a number, where higher numbers are better. The code below extracts some useful information from the state, like the remaining food (newFood) and Pacman position after moving (newPos). newScaredTimes holds the number of moves that each ghost will remain scared because of Pacman having eaten a power pellet. Print out these variables to see what you're getting, then combine them to create a masterful evaluation function. """ # Useful information you can extract from a GameState (pacman.py) successorGameState = currentGameState.generatePacmanSuccessor(action) newPos = successorGameState.getPacmanPosition() newFood = successorGameState.getFood() newGhostStates = successorGameState.getGhostStates() newScaredTimes = [ghostState.scaredTimer for ghostState in newGhostStates]
Now you will write an adversarial search agent in the provided MinimaxAgent class stub in multiAgents.py. Your minimax agent should work with any number of ghosts, so you’ll have to write an algorithm that is slightly more general than what you’ve previously seen in lecture. In particular, your minimax tree will have multiple min layers (one for each ghost) for every max layer.
Your code should also expand the game tree to an arbitrary depth. Score the leaves of your minimax tree with the supplied self.evaluationFunction, which defaults to scoreEvaluationFunction. MinimaxAgent extends MultiAgentSearchAgent, which gives access to self.depth and self.evaluationFunction. Make sure your minimax code makes reference to these two variables where appropriate as these variables are populated in response to command line options.
Important: A single search ply is considered to be one Pacman move and all the ghosts’ responses, so depth 2 search will involve Pacman and each ghost moving two times.
Grading: We will be checking your code to determine whether it explores the correct number of game states. This is the only reliable way to detect some very subtle bugs in implementations of minimax. As a result, the autograder will be very picky about how many times you call GameState.generateSuccessor. If you call it any more or less than necessary, the autograder will complain. To test and debug your code, run
1
python autograder.py -q q2
This will show what your algorithm does on a number of small trees, as well as a pacman game. To run it without graphics, use:
1
python autograder.py -q q2 --no-graphics
Hints and Observations
Implement the algorithm recursively using helper function(s).
The correct implementation of minimax will lead to Pacman losing the game in some tests. This is not a problem: as it is correct behaviour, it will pass the tests.
The evaluation function for the Pacman test in this part is already written (self.evaluationFunction). You shouldn’t change this function, but recognize that now we’re evaluating states rather than actions, as we were for the reflex agent. Look-ahead agents evaluate future states whereas reflex agents evaluate actions from the current state.
The minimax values of the initial state in the
1
minimaxClassic
layout are 9, 8, 7, -492 for depths 1, 2, 3 and 4 respectively. Note that your minimax agent will often win (665/1000 games for us) despite the dire prediction of depth 4 minimax.
1
python pacman.py -p MinimaxAgent -l minimaxClassic -a depth=4
Pacman is always agent 0, and the agents move in order of increasing agent index.
All states in minimax should be GameStates, either passed in to getAction or generated via GameState.generateSuccessor. In this project, you will not be abstracting to simplified states.
On larger boards such as openClassic and mediumClassic (the default), you’ll find Pacman to be good at not dying, but quite bad at winning. He’ll often thrash around without making progress. He might even thrash around right next to a dot without eating it because he doesn’t know where he’d go after eating that dot. Don’t worry if you see this behavior, question 5 will clean up all of these issues.
When Pacman believes that his death is unavoidable, he will try to end the game as soon as possible because of the constant penalty for living. Sometimes, this is the wrong thing to do with random ghosts, but minimax agents always assume the worst:
1
python pacman.py -p MinimaxAgent -l trappedClassic -a depth=3
Make sure you understand why Pacman rushes the closest ghost in this case.
Answer
Get all the ghosts’ index number
1
ghostIdx = [i for i inrange(1, gameState.getNumAgents())]
Set terminal conditions
1 2
defterm(state, depth): return state.isWin() or state.isLose() or depth == self.depth
Search for all the ghosts’ actions that lead to the Pacman’s benefit value minimum, if the current ghost is the last one, then we need to search for the Pacman at the next level to generate the maximum value for itself, otherwise, we just need to search for the next ghost’s action and find out the minimum.
1 2 3 4 5 6 7 8 9 10 11 12
defminValue(state, depth, ghost): if term(state, depth): return self.evaluationFunction(state)
value = 1e9 for action in state.getLegalActions(ghost): if ghost == ghostIdx[-1]: value = min(value, maxValue(state.generateSuccessor(ghost, action), depth + 1)) else: value = min(value, minValue(state.generateSuccessor(ghost, action), depth, ghost + 1))
return value
Search for the action that leads to the maximum value that the Pacman can get.
1 2 3 4 5 6 7 8 9
defmaxValue(state, depth): if term(state, depth): return self.evaluationFunction(state)
value = -1e9 for action in state.getLegalActions(0): value = max(value, minValue(state.generateSuccessor(0, action), depth, ghostIdx[0]))
return value
Bind the action and the value that the action generated, then sort the array by the value, return the maximum.
1 2 3 4
res = [(action, minValue(gameState.generateSuccessor(0, action), 0, ghostIdx[0])) for action in gameState.getLegalActions(0)] res.sort(key=lambda k: k[1])
classMinimaxAgent(MultiAgentSearchAgent): """ Your minimax agent (question 2) """
defgetAction(self, gameState: GameState): """ Returns the minimax action from the current gameState using self.depth and self.evaluationFunction. Here are some method calls that might be useful when implementing minimax. gameState.getLegalActions(agentIndex): Returns a list of legal actions for an agent agentIndex=0 means Pacman, ghosts are >= 1 gameState.generateSuccessor(agentIndex, action): Returns the successor game state after an agent takes an action gameState.getNumAgents(): Returns the total number of agents in the game gameState.isWin(): Returns whether or not the game state is a winning state gameState.isLose(): Returns whether or not the game state is a losing state """ "*** YOUR CODE HERE ***" # util.raiseNotDefined() ghostIdx = [i for i inrange(1, gameState.getNumAgents())]
defterm(state, depth): return state.isWin() or state.isLose() or depth == self.depth
defminValue(state, depth, ghost): if term(state, depth): return self.evaluationFunction(state)
value = 1e9 for action in state.getLegalActions(ghost): if ghost == ghostIdx[-1]: value = min(value, maxValue(state.generateSuccessor(ghost, action), depth + 1)) else: value = min(value, minValue(state.generateSuccessor(ghost, action), depth, ghost + 1))
return value
defmaxValue(state, depth): if term(state, depth): return self.evaluationFunction(state)
value = -1e9 for action in state.getLegalActions(0): value = max(value, minValue(state.generateSuccessor(0, action), depth, ghostIdx[0]))
return value
res = [(action, minValue(gameState.generateSuccessor(0, action), 0, ghostIdx[0])) \ for action in gameState.getLegalActions(0)] res.sort(key=lambda k: k[1])
return res[-1][0]
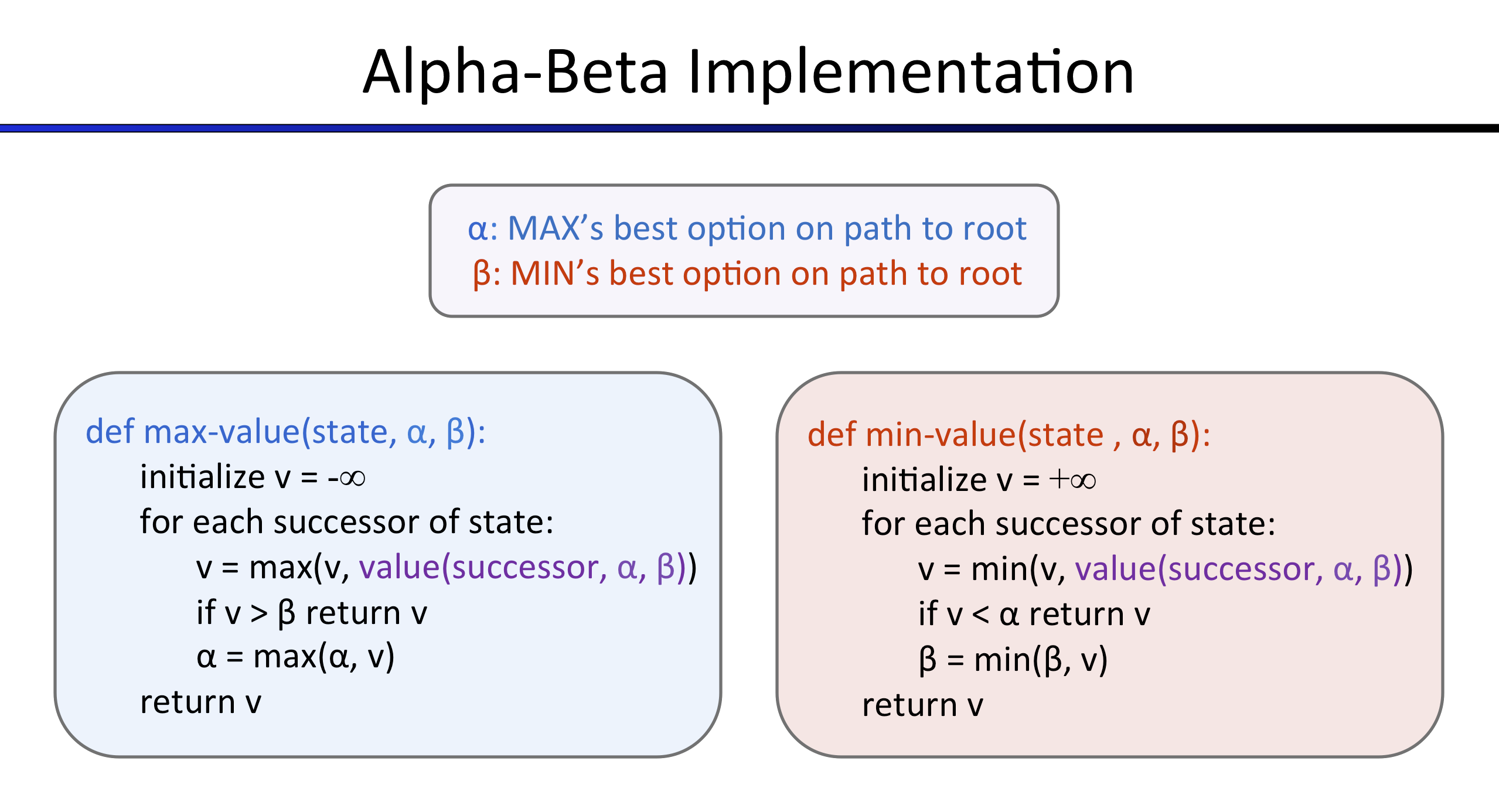
Q3 (5 pts): Alpha-Beta Pruning
Make a new agent that uses alpha-beta pruning to more efficiently explore the minimax tree, in AlphaBetaAgent. Again, your algorithm will be slightly more general than the pseudocode from lecture, so part of the challenge is to extend the alpha-beta pruning logic appropriately to multiple minimizer agents.
You should see a speed-up (perhaps depth 3 alpha-beta will run as fast as depth 2 minimax). Ideally, depth 3 on smallClassic should run in just a few seconds per move or faster.
1
python pacman.py -p AlphaBetaAgent -a depth=3 -l smallClassic
The AlphaBetaAgent minimax values should be identical to the MinimaxAgent minimax values, although the actions it selects can vary because of different tie-breaking behavior. Again, the minimax values of the initial state in the minimaxClassic layout are 9, 8, 7 and -492 for depths 1, 2, 3 and 4 respectively.
Grading: Because we check your code to determine whether it explores the correct number of states, it is important that you perform alpha-beta pruning without reordering children. In other words, successor states should always be processed in the order returned by GameState.getLegalActions. Again, do not call GameState.generateSuccessor more than necessary.
You must not prune on equality in order to match the set of states explored by our autograder. (Indeed, alternatively, but incompatible with our autograder, would be to also allow for pruning on equality and invoke alpha-beta once on each child of the root node, but this will not match the autograder.)
The pseudo-code below represents the algorithm you should implement for this question.
To test and debug your code, run
1
python autograder.py -q q3
This will show what your algorithm does on a number of small trees, as well as a pacman game. To run it without graphics, use:
1
python autograder.py -q q3 --no-graphics
The correct implementation of alpha-beta pruning will lead to Pacman losing some of the tests. This is not a problem: as it is correct behaviour, it will pass the tests.
Answer
Using self-defined function, alphaValue(), betaValue() to choose the most appropriate action
Only when it’s the final state, can we get the value of each node, using the self.evaluationFunction(gameState)
Otherwise, we just get the alpha/beta value we defined here.
defbetaValue(self, gameState, depth, agentIdx, alpha = -1e9, beta = 1e9): """ minParty, search for minimums """ value = 1e9 legalActions = gameState.getLegalActions(agentIdx) for index, action inenumerate(legalActions): if agentIdx == gameState.getNumAgents() - 1: nextValue = self.getNodeValue(gameState.generateSuccessor(agentIdx, action), \ depth + 1, 0, alpha, beta) value = min(value, nextValue) # begin next depth if value < alpha: return value else: nextValue = self.getNodeValue(gameState.generateSuccessor(agentIdx, action), \ depth, agentIdx + 1, alpha, beta) value = min(value, nextValue) # begin next depth if value < alpha: # next agent goes on at the same depth return value beta = min(beta, value) return value
defgetNodeValue(self, gameState, depth = 0, agentIdx = 0, alpha = -1e9, beta = 1e9): """ Using self-defined function, alphaValue(), betaValue() to choose the most appropriate action Only when it's the final state, can we get the value of each node, using the self.evaluationFunction(gameState) Otherwise we just get the alpha/beta value we defined here. """ maxParty = [0, ] minParty = list(range(1, gameState.getNumAgents()))
if depth == self.depth or gameState.isLose() or gameState.isWin(): return self.evaluationFunction(gameState) elif agentIdx in maxParty: return self.alphaValue(gameState, depth, agentIdx, alpha, beta) elif agentIdx in minParty: return self.betaValue(gameState, depth, agentIdx, alpha, beta)
defalphaValue(self, gameState, depth, agentIdx, alpha = -1e9, beta = 1e9): """ maxParty, search for maximums """ value = -1e9 legalActions = gameState.getLegalActions(agentIdx) for index, action inenumerate(legalActions): nextValue = self.getNodeValue(gameState.generateSuccessor(agentIdx, action), \ depth, agentIdx + 1, alpha, beta) value = max(value, nextValue) if value > beta: # next_agent in which party return value alpha = max(alpha, value) return value
defbetaValue(self, gameState, depth, agentIdx, alpha = -1e9, beta = 1e9): """ minParty, search for minimums """ value = 1e9 legalActions = gameState.getLegalActions(agentIdx) for index, action inenumerate(legalActions): if agentIdx == gameState.getNumAgents() - 1: nextValue = self.getNodeValue(gameState.generateSuccessor(agentIdx, action), \ depth + 1, 0, alpha, beta) value = min(value, nextValue) # begin next depth if value < alpha: return value else: nextValue = self.getNodeValue(gameState.generateSuccessor(agentIdx, action), \ depth, agentIdx + 1, alpha, beta) value = min(value, nextValue) # begin next depth if value < alpha: # next agent goes on at the same depth return value beta = min(beta, value) return value
Q4 (5 pts): Expectimax
Minimax and alpha-beta are great, but they both assume that you are playing against an adversary who makes optimal decisions. As anyone who has ever won tic-tac-toe can tell you, this is not always the case. In this question you will implement the ExpectimaxAgent, which is useful for modeling probabilistic behavior of agents who may make suboptimal choices.
As with the search and problems yet to be covered in this class, the beauty of these algorithms is their general applicability. To expedite your own development, we’ve supplied some test cases based on generic trees. You can debug your implementation on small the game trees using the command:
1
python autograder.py -q q4
Debugging on these small and manageable test cases is recommended and will help you to find bugs quickly.
Once your algorithm is working on small trees, you can observe its success in Pacman. Random ghosts are of course not optimal minimax agents, and so modeling them with minimax search may not be appropriate. ExpectimaxAgent will no longer take the min over all ghost actions, but the expectation according to your agent’s model of how the ghosts act. To simplify your code, assume you will only be running against an adversary which chooses amongst their getLegalActions uniformly at random.
To see how the ExpectimaxAgent behaves in Pacman, run:
1
python pacman.py -p ExpectimaxAgent -l minimaxClassic -a depth=3
You should now observe a more cavalier approach in close quarters with ghosts. In particular, if Pacman perceives that he could be trapped but might escape to grab a few more pieces of food, he’ll at least try. Investigate the results of these two scenarios:
You should find that your ExpectimaxAgent wins about half the time, while your AlphaBetaAgent always loses. Make sure you understand why the behavior here differs from the minimax case.
The correct implementation of expectimax will lead to Pacman losing some of the tests. This is not a problem: as it is correct behaviour, it will pass the tests.
Answer
1 2 3 4 5 6 7 8 9 10
maxValue = -1e9 maxAction = Directions.STOP
for action in gameState.getLegalActions(0): sucState = gameState.generateSuccessor(0, action) sucValue = self.getNodeValue(sucState, 0, 1) if sucValue > maxValue: maxValue, maxAction = sucValue, action
return maxAction
If the game state is the terminated, return the evaluation of the current state. Return the maximum value if the agent is the paceman, otherwise, return the expected value.
1 2 3 4 5 6 7 8
defgetNodeValue(self, gameState, curDepth, agentIndex): if curDepth == self.depth or gameState.isWin() or gameState.isLose(): return self.evaluationFunction(gameState)
classExpectimaxAgent(MultiAgentSearchAgent): """ Your expectimax agent (question 4) """
defgetAction(self, gameState: GameState): """ Returns the expectimax action using self.depth and self.evaluationFunction All ghosts should be modeled as choosing uniformly at random from their legal moves. """ "*** YOUR CODE HERE ***" # util.raiseNotDefined() maxValue = -1e9 maxAction = Directions.STOP
for action in gameState.getLegalActions(0): sucState = gameState.generateSuccessor(0, action) sucValue = self.getNodeValue(sucState, 0, 1) if sucValue > maxValue: maxValue, maxAction = sucValue, action
return maxAction
defgetNodeValue(self, gameState, curDepth, agentIndex): if curDepth == self.depth or gameState.isWin() or gameState.isLose(): return self.evaluationFunction(gameState)
Write a better evaluation function for Pacman in the provided function betterEvaluationFunction. The evaluation function should evaluate states, rather than actions like your reflex agent evaluation function did. With depth 2 search, your evaluation function should clear the smallClassic layout with one random ghost more than half the time and still run at a reasonable rate (to get full credit, Pacman should be averaging around 1000 points when he’s winning).
Grading: the autograder will run your agent on the smallClassic layout 10 times. We will assign points to your evaluation function in the following way:
If you win at least once without timing out the autograder, you receive 1 points. Any agent not satisfying these criteria will receive 0 points.
+1 for winning at least 5 times, +2 for winning all 10 times
+1 for an average score of at least 500, +2 for an average score of at least 1000 (including scores on lost games)
+1 if your games take on average less than 30 seconds on the autograder machine, when run with --no-graphics.
The additional points for average score and computation time will only be awarded if you win at least 5 times.
Please do not copy any files from Project 1, as it will not pass the autograder on Gradescope.
You can try your agent out under these conditions with
defbetterEvaluationFunction(currentGameState: GameState): """ Your extreme ghost-hunting, pellet-nabbing, food-gobbling, unstoppable evaluation function (question 5). DESCRIPTION: <write something here so we know what you did> """ "*** YOUR CODE HERE ***" # util.raiseNotDefined() newPos = currentGameState.getPacmanPosition() newFood = currentGameState.getFood() newGhostStates = currentGameState.getGhostStates()
# Consts INF = 100000000.0# Infinite value WEIGHT_FOOD = 10.0# Food base value WEIGHT_GHOST = -10.0# Ghost base value WEIGHT_SCARED_GHOST = 100.0# Scared ghost base value
# Base on gameState.getScore() score = currentGameState.getScore()
# Evaluate the distance to the closest food distancesToFoodList = [util.manhattanDistance(newPos, foodPos) for foodPos in newFood.asList()] iflen(distancesToFoodList) > 0: score += WEIGHT_FOOD / min(distancesToFoodList) else: score += WEIGHT_FOOD
# Evaluate the distance to ghosts for ghost in newGhostStates: distance = manhattanDistance(newPos, ghost.getPosition()) if distance > 0: if ghost.scaredTimer > 0: # If scared, add points score += WEIGHT_SCARED_GHOST / distance else: # If not, decrease points score += WEIGHT_GHOST / distance else: return -INF # Pacman is dead at this point